

本公式适用于Windows7+环境,WPS 2016及以上版本 或 Excel 2007及以上版本
GetWebContentById(Url, Element_id, [Encoding], [Method], [Headers])。根据网页元素id查找指定网页Url中的数据。Encoding指网页编码,默认GB2312;Method指访问类型包括GET或POST两种方式,默认GET方式;Headers指请求头,多个Header每一行放置一个,例如Host: open.onebox.so.com
GetWebContentByClassName(Url, Element_id,[Encoding], [Method], [Headers])。根据网页元素的样式class属性查找指定网页Url中的数据。
案例演示
按照ExcelHome帖子的网址查找帖子中的标题,最效果如下:
按照样式属性名称查找=GetWebContentByClassName(A1,"ts")
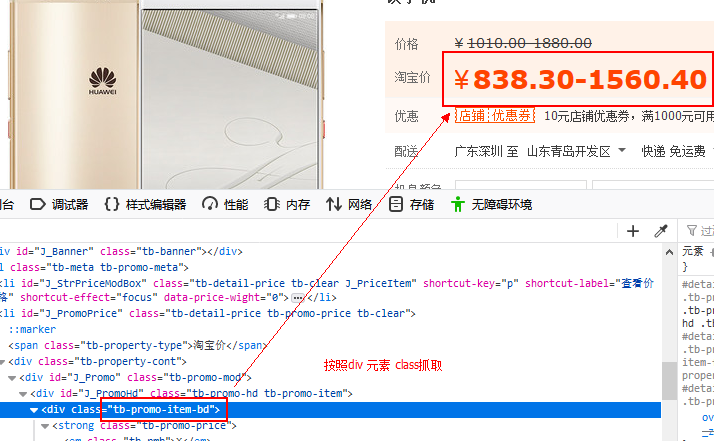
按照元素id查找=GetWebContentById(A2,"thread_subject")
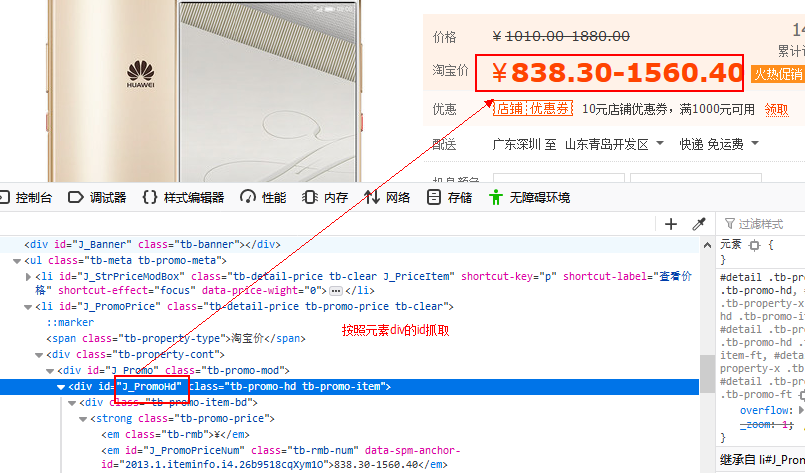
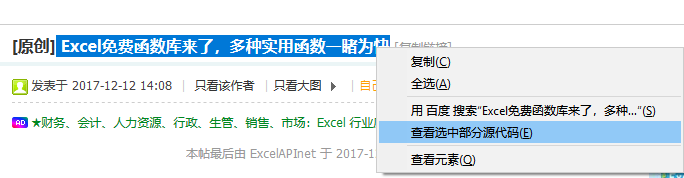
使用这两个函数也非常简单,主要是找到按照网页源码查找规律,找到目标数据所在的位置,位置一般通过id或class来确定。在火狐狸浏览器中可通过右键-查看选中代码查看,如下图所示。其中ts和thread_subject就是我们需要的class name和id。

是不是很简单,只要会写公式就有可能抓取到网页的数据。
查询IP地址
=GetWebContentByClassName("http://www.ip138.com/ips138.asp?ip=114.114.114.114&action=2","ul1")
=GetWebContentByClassName("http://ip.tool.chinaz.com/114.114.114.114","Whwtdhalf w50-0",0,"UTF-8")
查询手机号码归属地
=GetWebContentByClassName("http://www.ip138.com:8080/search.asp?mobile=13588981234&action=mobile","tdc2",2)
如果出现网页乱码,可以使用RemoveHtmlTags公司移除
=RemoveHtmlTags(“浙江 温州市”)结果是“浙江 温州市”
友情提醒:注意替换IP地址或手机号。